进一步接近人的智能:多模态机器学习
人和动物通过视、听、说等途径感知和学习,本质上是多模态学习。近些年,由于深度学习的发展,多模态机器学习进一步成为人工智能的研究热点。本文简单介绍多模态机器学习的内容和挑战,部分摘于CVPR 2016 和ACL 2016的Tutorial Multimodal Learning and Reasoning [1], Tutorial on Multimodal Machine Learning [2]。
人在生活中的感知是多元的,包括视觉、听觉、触觉、味觉、嗅觉等等。任何感知能力的缺失都有可能造成智力或能力的异常。
基于此,多模态机器学习(Multimodal Machine Learning) 为机器提供多模态数据处理能力。例如,看图说话,看电影翻译。多模态学习的长远目标是使机器充分感知环境,如感知人的情感、言辞、表情,更智能地和环境进行交互。
目前,学术上比较成熟的是视觉和语义之间的多模态学习。如对一张图片生成文字描述,或者针对一张图片的内容回答相应的文字问题。视觉信息通常用CNN处理,文本信息通畅使用RNN处理。多维度数据对齐的方式有attention机制,例如,看图说话里名词对应图里面哪个物体。并且,在很多传统机器学习任务上,多模态学习优于单模态机器学习,例如,辅助视觉信息的文本翻译效果优于仅使用文本信息。
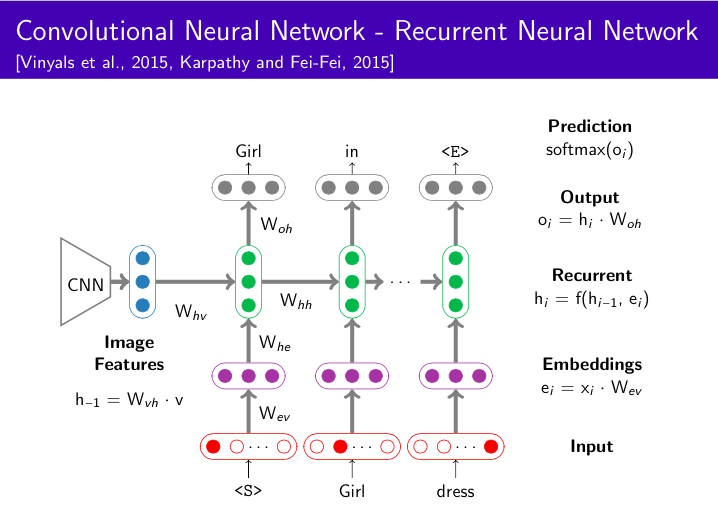
当然,现在多模态机器学习还存在很多挑战。包括多维度数据的各自表示、融合、对齐、协同学习,还有待学术理论的丰富和完善,但应用前景非常广泛。
[1] https://sites.google.com/site/multiml2016cvpr/
[2] http://acl2016.org/index.php?article_id=59