智能机器人的新范式:深度强化学习
近两年机器智能取得重大突破,像围棋九段高手李世石败北Alpha Go,DeepMind团队研发的机器人在Atari 多项游戏上超越人类水平。主要得益于从基于深度学习的视觉、语音、语义感知到动作反馈的激励惩罚强化训练模式。本文从概念上分析深度强化学习的要点,部分摘于ICML 2016 Tutorial里的Deep Reinforcement Learning [1]的报告。
强化学习,即机器人根据环境里动作得到的惩罚和激励去自动调整策略。通过训练,机器人学到一组策略:在环境状态S下应采取动作A,(可)能获得最大累积奖励V。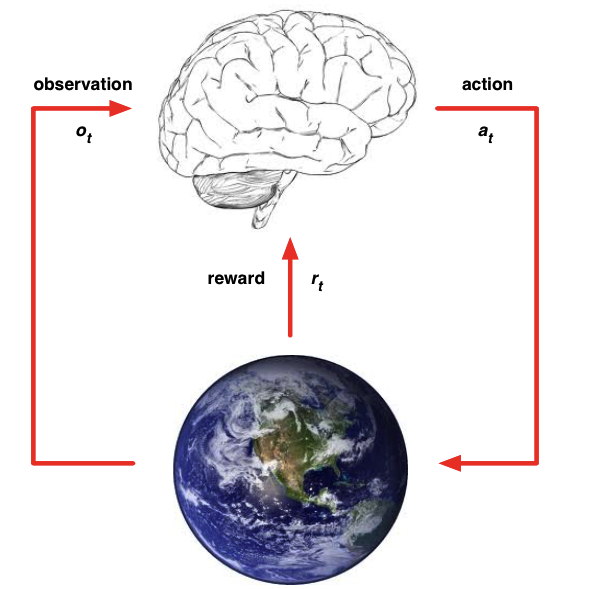
强化学习有丰富的交叉学科背景,包括经济学、工程学、神经科学里的博弈论、优化控制,条件反射系统。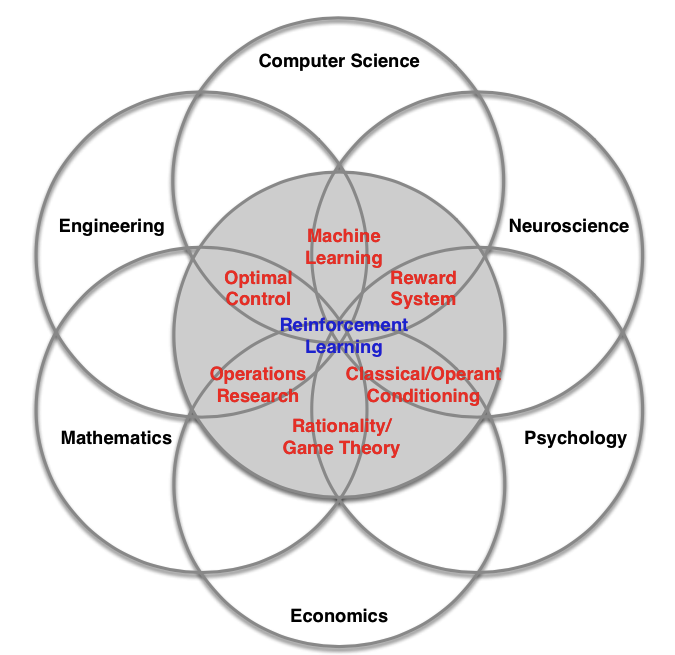
深度学习,使用深度神经网络实现机器人的记忆,视觉感知,语音语义理解和生成。从概念上对深度学习的理解可以参考链接: http://toutiao.com/i6319415390225039873/ 。
深度强化学习以深度学习做感知,强化学习训练策略,并且以深度神经网络作为策略载体。相比于传统的多模块组合,深度强化学习实现了从感知到控制的端到端直接训练,减少了模块间信息损失。
最近两年在学术理论上,Google DeepMind团队在连续性动作控制[2],异步训练[3],训练框架[4],分布式训练[5]等都有重要突破,为智能机器人的研发奠定理论和实践基础。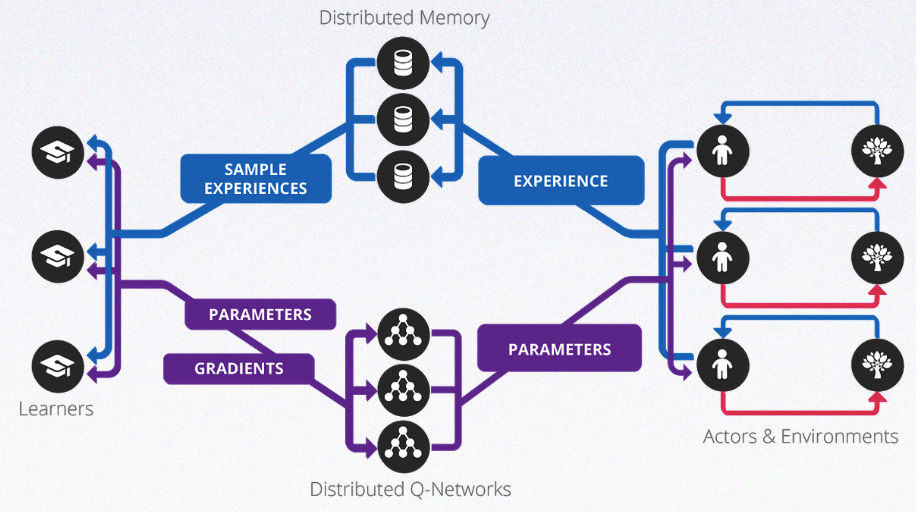
在特定任务的应用上,深度增强学习已有广泛实践尝试,例如流水线机器人。
在集成应用上,深度强化学习在自动驾驶,聊天机器人[6][7]都有良好的前景。例如,使用分布式训练或异步训练,自动驾驶汽车可以多辆同时在各种环境学习,并且相互交换知识,加速学习过程。聊天机器人可以通过对话过程中用户的反馈来调整自己的语言表达,逐步成长。
深度强化学习为智能机器人提供了新的计算范式:提供环境、激励和惩罚、神经网络结构即可训练得到最大化奖励的智能机器人。
[1] icml.cc/2016/tutorials/deep_rl_tutorial.pdf
[2] 2016 ICML Continuous Deep Q-Learning with Model-based Acceleration
[3] 2016 ICML Asynchronous Methods for Deep Reinforcement Learning
[4] 2016 ICML Dueling Network Architectures for Deep Reinforcement Learning
[5] 2015 ICMLW Massively Parallel Methods for Deep Reinforcement Learning
[6] 2016 ICLR DEEP REINFORCEMENT LEARNING WITH AN ACTION SPACE DEFINED BY NATURAL LANGUAGE
[7] 2016 Deep Reinforcement Learning for Dialogue Generation